
大数据开发作为当今技术领域的核心方向之一,其学习路径需要兼顾理论深度与实践广度。随着Hadoop、Spark等框架的普及,企业对开发者的要求已从单一工具使用转向全链路数据处理能力。自学大数据开发需突破三大核心难点:分布式计算原理的抽象性、技术栈的碎片化以及实战场景的缺失。学习者需构建"底层原理-工具应用-业务落地"的三层知识体系,并通过多平台交叉验证提升解决复杂问题的能力。
猜你喜欢
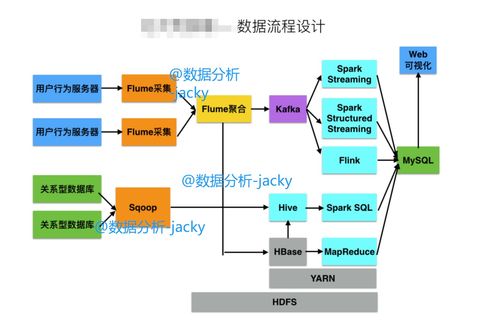
一、大数据开发核心技术图谱
| 技术领域 | 核心组件 | 典型应用场景 |
|---|---|---|
| 数据采集 | Flume/Logstash/Kafka | 实时日志收集、多源数据汇聚 |
| 数据存储 | HDFS/Ceph/MinIO | 海量文件存储、冷数据归档 |
| 计算引擎 | MapReduce/Spark/Flink | 批处理/流处理/图计算 |
| 数据治理 | Hive/HBase/Elasticsearch | 元数据管理、实时查询 |
| 任务调度 | Oozie/Airflow/DolphinScheduler | 工作流编排、资源调度 |
二、自学路径阶段性规划
| 学习阶段 | 核心目标 | 验证方式 |
|---|---|---|
| 基础筑基(1-3月) | 掌握Linux/Java基础,理解分布式原理 | 搭建伪分布式Hadoop环境,实现WordCount |
| 框架精通(4-6月) | 熟练使用Spark/Flink完成ETL开发 | 复现Kaggle数据集处理案例 |
| 架构进阶(7-9月) | 设计高可用数据管道,优化Shuffle过程 | 参与开源项目代码贡献(如Apache DolphinScheduler) |
| 实战淬炼(10-12月) | 完成电商/金融领域完整数据项目 | 通过阿里云/腾讯云大数据认证考试 |
三、主流平台特性对比
| 维度 | Hadoop生态 | Cloudera Altus | AWS EMR |
|---|---|---|---|
| 部署复杂度 | 需手动配置YARN/HDFS | 可视化集群管理 | 一键部署托管服务 |
| 成本结构 | 硬件采购+运维人力 | 订阅制软件授权 | 按需实例计费 |
| 扩展能力 | 线性扩展节点 | 自动弹性伸缩 | 秒级扩容缩容 |
| 适用场景 | 离线分析/历史归档 | 混合云架构实施 | 突发流量处理 |
在技术选型层面,Hadoop适合构建私有化数据中台,其MR模型对理解分布式计算具有教学价值;Spark凭借内存计算优势成为实时分析首选,但需注意Checkpoint机制对状态管理的影响;Flink的精确一次处理能力使其在金融风控领域表现突出。学习者应通过GitHub Actions自动化测试对比不同框架的吞吐量与延迟特性。
四、学习资源矩阵
- 文档类:Apache官方文档(版本迭代说明)、Cloudera工程实践指南
- 视频课程:Coursera《大数据系统概论》、极客时间《Spark内核解析》
- 实战平台:Kaggle竞赛数据集、天池大数据大赛、本地Docker容器集群
有效的学习节奏应遵循"概念验证→功能实现→性能调优"的递进模式。例如学习Spark时,先通过本地模式运行基础算子,再在Standalone集群验证任务调度,最后通过动态资源分配优化Executor配置。建议每周保留固定时间进行 构建个人知识库时建议采用Notion+Obsidian组合,通过双向链接关联HDFS架构图与YARN资源调度算法。每日记录 当完成个人作品集后,可通过以下方式检验学习成果:在GitHub创建完整的数据管道项目(含单元测试与Dockerfile);在技术社区发起框架对比测评(如Spark VS Flink的窗口运算效率);参与开源项目Bug修复(优先选择Documentation类Issue)。持续半年以上的系统学习,配合200+小时的代码实践,即可达到初级大数据工程师的入职门槛。 本文采摘于网络,不代表本站立场,转载联系作者并注明出处:https://www.xhlnet.com/jisuanji/16858.html常见问题 解决方案 原理解析 数据倾斜导致任务卡顿 预分区+Salting策略 哈希分布不均时的负载均衡
- 哪些电脑培训学校比较好(电脑培训优质选择)
- 江西省新华电脑学校(江西省新华电脑学校)
- 浏阳哪里有电脑培训学校(浏阳电脑培训学校地址)
- 信阳方正电脑学校(信阳电脑技术培训中心)
- 芜湖万达电脑培训学校(芜湖万达电脑培训)
- 赣州新起点电脑设计培训学校怎么样(赣州新起点电脑学校评价)
- 湖南电脑培训学校(湖南计算机培训中心)
- 营口向阳电脑学校(营口向阳电脑学校)
- 潍坊天和电脑培训学校(潍坊天和电脑培训学校)
- 云南新华电脑培训学校(云南新华电脑培训学校)
- 西安计算机学校排行榜(西安计算机学校排名)
- 贵阳市计算机职业学校(贵阳市计算机职业技术学校)
- 上海大学
- 上海外国语大学
- 东华大学
- 华东理工大学
- 上海财经大学
- 新疆大学
- 黔东南理工职业学院
- 北京林业大学
- 北京中医药大学
- 北京化工大学
- 北京交通大学
- 北京科技大学
- 中国矿业大学(北京)
- 北京体育大学
- 中央音乐学院
- 北京工业大学
- 对外经济贸易大学
- 中央财经大学
- 中国石油大学(北京)
- 中国传媒大学
- 北京邮电大学
- 中国政法大学
- 北京外国语大学
- 华北电力大学
- 河海大学
- 南京航空航天大学
- 南京农业大学
- 南京师范大学
- 中国药科大学
- 南京理工大学
- 广西大学
- 南昌大学
- 安徽大学
- 合肥工业大学
- 内蒙古大学
- 东北农业大学
- 哈尔滨工程大学
- 东北林业大学
- 大连海事大学
- 天津医科大学
- 河北工业大学
- 华南师范大学
- 暨南大学
- 延边大学
- 电子科技大学
- 西南财经大学
- 西南交通大学
- 西藏大学
- 江南大学
- 云南大学
- 太原理工大学
- 华中师范大学
- 武汉理工大学
- 华中农业大学
- 中南财经政法大学
- 中国地质大学(武汉)
- 辽宁大学
- 海南大学
- 石河子大学
- 福州大学
- 苏州大学
- 青海大学
- 长安大学
- 西北大学
- 西安电子科技大学
- 陕西师范大学
- 贵州大学
- 郑州大学
- 西南大学
- 宁夏大学
- 东北师范大学
- 湖南师范大学
- 四川农业大学
- 上海交通大学
- 华东师范大学
- 同济大学
- 复旦大学
- 兰州大学
- 北京师范大学
- 北京航空航天大学
- 中国农业大学
- 清华大学
- 北京理工大学
- 中国人民大学
- 中央民族大学
- 北京大学
- 南京大学
- 东南大学
- 厦门大学
- 中国科学技术大学
- 西北农林科技大学
- 哈尔滨工业大学
- 大连理工大学
- 天津大学
- 南开大学
- 中山大学
- 华南理工大学
- 四川大学
- 浙江大学
- 武汉大学
- 华中科技大学
- 东北大学
- 山东大学
- 西北工业大学
- 西安交通大学
- 重庆大学
- 吉林大学
- 湖南大学
- 国防科技大学
- 中南大学
- 中国海洋大学
展开全部
- 西藏大学
- 西北大学
- 西安交通大学
- 西北工业大学
- 西安电子科技大学
- 长安大学
- 西北农林科技大学
- 陕西师范大学
- 兰州大学
- 青海大学
- 宁夏大学
- 新疆大学
- 石河子大学
- 厦门大学
- 福州大学
- 南昌大学
- 山东大学
- 中国海洋大学
- 郑州大学
- 河南大学
- 武汉大学
- 华中科技大学
- 武汉理工大学
- 华中农业大学
- 华中师范大学
- 中南财经政法大学
- 湘潭大学
- 湖南大学
- 中南大学
- 湖南师范大学
- 中山大学
- 暨南大学
- 华南理工大学
- 华南农业大学
- 广州医科大学
- 广州中医药大学
- 华南师范大学
- 南方科技大学
- 广西大学
- 海南大学
- 重庆大学
- 西南大学
- 四川大学
- 西南交通大学
- 西南石油大学
- 成都理工大学
- 四川农业大学
- 成都中医药大学
- 西南财经大学
- 贵州大学
- 北京大学
- 中国人民大学
- 清华大学
- 北京交通大学
- 北京工业大学
- 北京理工大学
- 北京科技大学
- 北京化工大学
- 北京邮电大学
- 中国农业大学
- 北京林业大学
- 北京协和医学院
- 北京中医药大学
- 北京师范大学
- 首都师范大学
- 北京外国语大学
- 中国传媒大学
- 中央财经大学
- 对外经济贸易大学
- 外交学院
- 中国人民公安大学
- 北京体育大学
- 中央音乐学院
- 中国音乐学院
- 中央美术学院
- 中央戏剧学院
- 中央民族大学
- 中国政法大学
- 华北电力大学
- 中国石油大学(北京)
- 中国地质大学(北京)
- 中国科学院大学
- 南开大学
- 天津大学
- 天津工业大学
- 天津医科大学
- 天津中医药大学
- 河北工业大学
- 山西大学
- 太原理工大学
- 内蒙古大学
- 辽宁大学
- 大连理工大学
- 东北大学
- 大连海事大学
- 吉林大学
- 延边大学
- 东北师范大学
- 哈尔滨工业大学
- 哈尔滨工程大学
- 东北农业大学
- 东北林业大学
- 复旦大学
- 同济大学
- 上海交通大学
- 华东理工大学
- 东华大学
- 上海海洋大学
- 上海中医药大学
- 华东师范大学
- 上海外国语大学
- 上海财经大学
- 上海体育大学
- 上海音乐学院
- 上海大学
- 上海科技大学
- 南京大学
- 苏州大学
- 东南大学
- 南京航空航天大学
- 南京理工大学
- 中国矿业大学
- 南京邮电大学
- 河海大学
- 江南大学
- 南京林业大学
- 南京信息工程大学
- 南京农业大学
- 南京医科大学
- 南京中医药大学
- 中国药科大学
- 南京师范大学
- 浙江大学
- 中国美术学院
- 宁波大学
- 安徽大学
- 中国科学技术大学
- 合肥工业大学
- 国防科技大学
- 云南大学
展开全部